
Spatial Signals | 6.29.2025
Weekly insights into the convergence of spatial computing + AI

Welcome to ‘Spatial Signals’ by Dream Machines — a weekly snapshot of what matters most in Spatial Computing + AI.
This week’s TLDR:
Perk up and pay attention, because the world is changing. Fast.
First time reader? Sign up here.
1) Remote touch is becoming real—and it could revolutionize knowledge transfer
Training someone hands-on used to require... being hands-on. But a new protocol is rethinking that entirely—bringing physical mentorship into the virtual world.
It’s early days, but it’s called the “Mimicking Milly Protocol”, a system designed to enable real-time, remote physical interaction through XR and synchronized haptic feedback.
Here’s the core idea: a senior user—say, a surgeon, engineer, or technician—can guide someone else’s hands remotely. Not just visually, but physically. Force, angle, pressure—all transmitted live over a shared virtual model. The trainee doesn’t just see what to do. They feel it.
It’s remote mentorship 2.0.
The protocol is hardware-neutral and latency-resilient, using predictive motion syncing to smooth the experience across networks. Over time, it helps users build real muscle memory—not just mental recall.
Initial applications are focused on surgical training. But the implications are wide: from industrial assembly and prototyping to robotics, remote repair, and immersive education.
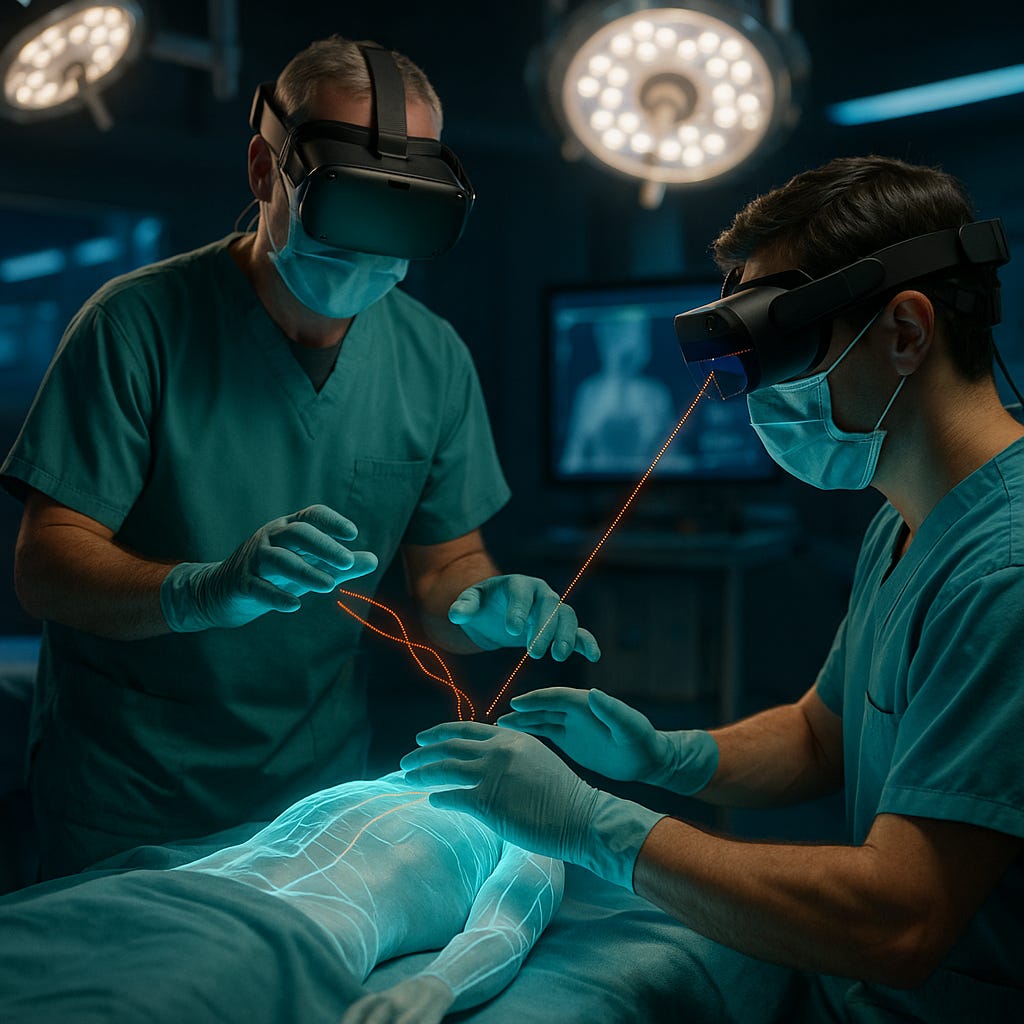
So what?
Most XR training systems stop at “watch and copy.” Mimicking Milly pushes into a new frontier: transferrable touch. It’s a powerful upgrade to what’s possible in remote work, physical skill-building, and collaborative creation.
If you’re building for training, field ops, or spatial robotics—keep your eye on this. The future of skill won’t just be taught. It’ll be transmitted.
(2) What if robots could imagine the world—before acting in it?
That’s the bold idea behind 1X’s new world model, a learned simulator that lets robots “dream” about the consequences of their actions before taking them.
Instead of relying on traditional physics engines or sterile digital twins, 1X trained its world model directly from thousands of hours of real-world video data. Their humanoid robots (EVE) performed everyday manipulation tasks—folding shirts, opening drawers, moving boxes—and that data became the foundation for the model’s predictive power.
Now, 1X’s world model can simulate multiple possible futures from a single moment. It predicts how objects will respond to different actions—capturing rigid, deformable, and articulated interactions with surprising realism.
The payoff? Robots can test, evaluate, and refine their behavior inside a learned simulator—before touching the real world. This solves one of robotics’ biggest headaches: scalable evaluation in dynamic environments.
Challenges remain. The model struggles with object consistency, physical laws, and self-awareness. But 1X is pushing the field forward by releasing a massive dataset, baseline models, and launching the 1X World Model Challenge—a three-part competition with cash prizes for breakthroughs in compression, sampling, and predictive evaluation.
So what?
This flips the robotics paradigm. Rather than building a perfect digital twin, 1X teaches robots to dream their own world—and act inside it.
If this scales, it could massively reduce the cost and complexity of deploying autonomous robots in real-world environments. It could also spark the “ChatGPT moment” for robotics—where embodied intelligence scales not just with code, but with lived experience. If robots can simulate reality well enough to train themselves, the age of general-purpose autonomy may be closer than it looks.
(3) What if spatial sensing could help prevent the next school shooting?
That’s the mission behind Cover, a startup redesigning weapons detection from the ground up—using advanced radar, AI, and spatial sensing to identify concealed threats from a distance, without disrupting daily life. See their Master Plan here.

Unlike airport-style scanners, Cover isn’t building metal detectors. It’s building invisible safety infrastructure—systems that can scan for hidden weapons under clothes or in backpacks from up to 4–5 meters away, while students simply walk through school entrances.
The technical bar is high: scanning through fabric and bags requires a ~10x leap in radar resolution, combined with AI that can clean up noisy images and flag weapons with ultra-low false positives.
But Cover’s just announced that their second-generation hardware is already showing breakthroughs:
Projected system cost down 90%—making nationwide scale viable
10x wider field of view—covering entire entryways, not just doorways
Real-time AI-powered detection—no bottlenecks, no manual screening
To reach these milestones, the team radically pivoted their engineering approach last year. The first full-scale system is on track for deployment by year-end.
So what?
For schools and public venues, Cover could offer a new kind of safety infrastructure: passive, fast, ambient—and designed for real-world dynamics. It’s not just selling scanners—it’s building a platform for ambient threat detection, one that could extend to malls, stadiums, and public spaces.
The business opportunity is massive. But the human impact is deeper: if we can make places feel safe without making them feel like prisons, we change what safety looks like.
The ethical tightrope is real: privacy, consent, surveillance. But so is the potential to save lives without turning schools into security zones.
The implications?
For business…
What if your spaces could sense threats—without ever breaking the flow daily work & life? (for customers & employees)
That’s the emerging promise of spatial sensing: intelligent environments that don’t wait for danger to announce itself, but quietly perceive it as it enters. No pat-downs. No bottlenecks. Just ambient, invisible awareness woven into the architecture of everyday places.
Real-time radar, AI, and multimodal perception are headed—turning cameras, sensors, and spatial computing into a distributed nervous system for public safety.
The opportunity:
If you operate high-traffic physical spaces—schools, campuses, airports, stadiums, factories—this isn’t just about security. It’s about user experience, brand trust, and operational resilience. You can replace reactive, high-friction screening systems with proactive, passive protection.Key questions for your team:
• Where does your current safety strategy create friction—or fear?
• How could real-time sensing enhance trust without increasing intrusion?
• Could ambient intelligence become a core feature of your physical product or environment?The future of safety won’t be seen. It will be sensed—calmly, constantly, and without interruption. Because the most effective security doesn’t just stop threats. It helps people feel like there weren’t any to begin with.
For life…
What if your hands could feel another person’s mind?
We’re entering an era where guidance is no longer spoken—it’s felt.
Through remote haptics and real-time motion syncing, expertise can now move across space. A surgeon doesn’t tell you how—they show you, force by force, pressure by pressure, through your own limbs. A technician can correct your angle from thousands of miles away.
Skill, once passed down through years of repetition, can now be transmitted—directly into the body.
But if precision arrives without struggle, do we still build confidence—or just coordination? When learning becomes frictionless, what happens to the humility, patience, and mistakes that shaped who we are?
Because learning was never just about the destination. It was about becoming someone on the way there.
But if machines can transmit mastery better than we can teach it—
what becomes of experience? Of intuition? Of effort? When the loop between intention and action is shortened to zero, will we still feel like the ones doing the doing?Maybe the real cost of effortless learning… is forgetting where the effort came from.
Favorite Content of the Week
Video + Tweet | AI Legend, Andrej Karpathy Keynote at AI Startup School
If you want to quickly level up your thinking on AI — the what, how, why — watch this video. But if you don’t have time…
Here are the key ideas:
LLMs are a new kind of computer— Large Language Models mark a fundamental shift in software. You program them in English, making natural language the new interface. This isn’t just a tool upgrade—it’s a paradigm shift in how we build and think about code.
They behave like OS’s, utilities, and fab labs— LLMs blur the lines between operating systems, fabrication plants, and cloud utilities. They're centralized, foundational, and massively distributed—placing us in a new computing era that feels a lot like the 1960s all over again.
LLMs are "people spirits"—stochastic simulations of human psychology. They’re eerily intuitive, sometimes superhuman, but also full of quirks and flaws. They’re not conscious, but they mirror our psychology. That makes collaboration possible… and complicated. Also…. These "people spirits" enable partially autonomous software. You’re no longer just building tools—you’re shaping behavior. Products can now act on our behalf.
Don’t just build products for users—build ecosystems for agents.
LLMs have become a third interface layer in computing: GUIs are for humans, APIs are for programs, and now LLMs interact with information directly. They’re not just tools—they’re participants.